Si vous avez un blog semi-populaire, il y a de fortes chances que quelques sites scrapers copient vos articles directement depuis votre flux. Lorsque vous surprenez un site à faire cela, vous serez probablement assez contrarié au début, étant donné qu'ils ont simplement copié tout votre travail acharné, et ne vous ont probablement même pas crédité. Au lieu de vous fâcher, prenez votre revanche.
Dans cet article, je vais passer en revue quelques façons de faire exactement cela dans WordPress en créant des liens vers votre blog (même lorsque le scraper a commodément « oublié » de vous créditer) :
- Comment utiliser le plugin RSS Footer pour insérer des liens (ou tout autre contenu que vous souhaitez) directement dans votre flux.
- Comment utiliser FeedBurner FeedFlares pour insérer des liens de bookmarking social dans vos flux, ainsi que vos propres flares personnalisés.
- Comment installer YARPP (Yet Another Related Posts Plugin) pour insérer automatiquement des liens vers des articles similaires dans votre flux.
Lisez la suite pour voir le reste, il y a aussi une vidéo...
Pied de page RSS
Ce plugin RSS Footer de Yoast est une solution populaire pour ajouter des messages de copyright et d'autres messages (y compris des publicités et des liens) à vos flux. Il est assez simple à configurer, après avoir installé le plugin, personnalisez simplement le message que vous souhaitez voir apparaître dans le pied de page RSS de vos articles.
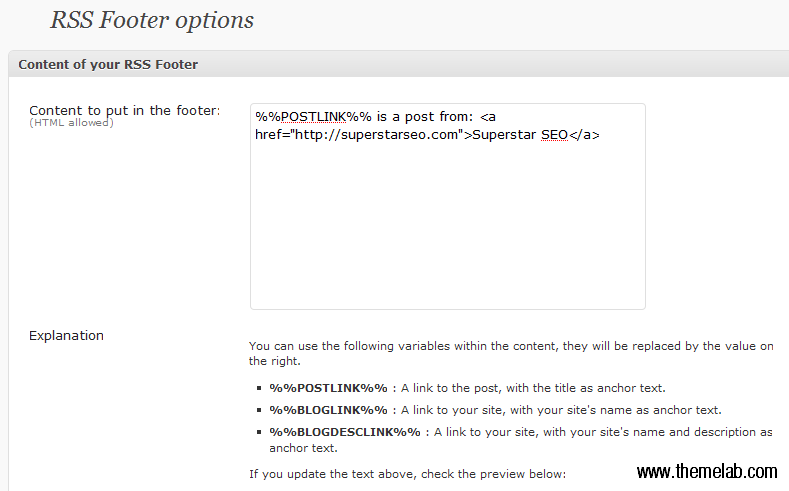
Le message par défaut dans la capture d'écran comprend un lien vers votre article, ainsi qu'un lien de retour vers votre blog. Il existe également un certain nombre d'autres paramètres, mais le seul qui doit vraiment être dynamique est celui de %%POSTLINK%%.
J'ai vu des gens y mettre des publicités illustrées, encore plus de liens textuels vers des pages de leur site, et des messages comme « Cet article a été volé par un scraper. » Gardez à l'esprit que ces messages apparaîtront non seulement sur les splogs qui scrapent votre site, mais aussi dans votre flux (où les gens réels le voient).
Cela dit, je ne recommanderais probablement pas des messages comme « Ce message a été volé par un scraper » car vos abonnés RSS humains pourraient ne pas comprendre ce que cela signifie.
Yet Another Related Posts Plugin
C'est un plugin que je recommande pour presque tous les blogs. En gros, si vous avez suffisamment d'articles pour avoir des articles similaires, utilisez YARPP. Il est pratiquement garanti de garder les visiteurs plus longtemps sur votre site, car ils ont tendance à cliquer sur les différents articles similaires pour trouver plus de contenu.
Lors de la première installation, vous remarquerez peut-être qu'il ne détecte aucun article similaire au début (même lorsque vous avez une tonne d'articles de blog). Cela est probablement dû au fait que le "seuil de correspondance" est réglé trop haut, ou que le cache des articles similaires n'a pas encore été créé. Consultez la FAQ de YARPP pour plus d'informations à ce sujet.
Après l'avoir installé, vous avez la possibilité d'afficher automatiquement les articles sur votre blog, ainsi que dans votre flux. Non seulement cela permet de réduire les taux de rebond, mais c'est aussi un bon moyen d'obtenir des liens profonds vers votre site à partir de tous les scrapers automatisés qui volent votre contenu.
Pied de page RSS + Screencast YARPP
Dans ce screencast, j'installe le plugin RSS footer et j'examine certains des paramètres. Je montre également comment j'ai configuré mes paramètres YARPP ici sur Theme Lab, ainsi que l'option d'afficher les articles similaires dans les flux.
Bonus : FeedBurner FeedFlare
FeedBurner FeedFlare est un service fourni par, vous l'avez deviné, FeedBurner. Si vous avez déjà vu des liens comme "Enregistrer cet article sur Delicious" ou des comptes de commentaires dynamiques dans les flux, c'est comme ça que ça marche.
Après avoir configuré votre flux FeedBurner, allez dans l'onglet "Optimiser" de votre compte et activez FeedFlare. À partir de là, il y a quelques FeedFlares "officiels" que vous pouvez utiliser.
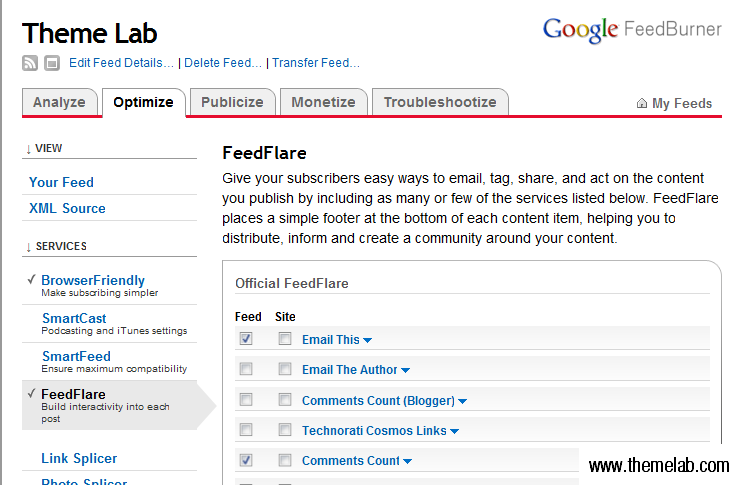
Sur Theme Lab, j'utilise : Email This, Comments Count, et Save to Delicious, ainsi que quelques options personnalisées avec un lien de retour vers ma page d'accueil et vers mon Twitter. Avec le recul, il serait peut-être préférable de lier ces deux-là avec le RSS Footer mentionné précédemment.
Cependant, si vous souhaitez configurer vos propres liens FeedFlare personnalisés comme les miens, quelle meilleure façon y aurait-il que de consulter les fichiers XML que j'utilise moi-même ?
Une fois que vous aurez modifié les fichiers XML pour votre propre usage (sauf si vous souhaitez des liens vers moi dans chacun de vos articles), téléchargez-les simplement sur votre serveur et collez les URL dans la boîte « Ajouter une nouvelle Flare ».
Liens internes
En plus de ces techniques qui facilitent évidemment beaucoup les choses, il est également judicieux d'inclure des liens internes dans vos articles. Vous remarquerez que je le fais assez souvent lorsque je publie un article.
Vous pourriez également utiliser un plugin comme Internal Link Building (nécessite de s'abonner à leur RSS pour télécharger) pour configurer automatiquement des liens pour certains mots-clés.
Comme toujours, à utiliser avec modération.
Conclusion
Je n'ai personnellement pas utilisé cela auparavant, mais Tynt semble être recommandé lorsqu'il s'agit de traiter avec les scrapers. Si quelqu'un a de l'expérience avec cela, j'aimerais le savoir dans les commentaires.
Maintenant, je suis sûr que certaines personnes ne seront pas d'accord avec moi sur ma position concernant les scrapers. Je déteste le plagiat autant que tout le monde. Le point que j'essaie de faire est, au lieu de perdre du temps à essayer de combattre les scrapers, pourquoi ne pas mettre en place YARPP, un pied de page RSS, d'autres liens internes, et les utiliser à votre avantage à la place ?
Je ne pense vraiment pas que passer aux extraits soit la solution, par opposition aux flux complets. Vous pourriez dissuader les scrapers, mais agacer vos abonnés RSS en même temps. Qu'est-ce qui est le plus important ?

Salut, vous parlez de profiter des scrapers en utilisant YARP (ce que je fais). Mais les sites Web des scrapers ne sont-ils pas un mauvais quartier pour obtenir des backlinks ?
C'est une bonne question, mais j'espère que cela n'aurait pas d'importance qu'un "mauvais quartier" vous lie, tant que vous ne leur renvoyez pas de lien.
Vous pourriez également voir des pingbacks/trackbacks provenant des sites de scrapers, mais je ne les approuverais pas, même s'il s'agit de liens nofollow.
De rien ! Heureux d'avoir pu inclure cette astuce utile dans mon résumé pour mes lecteurs et visiteurs. C'est vrai, cela n'est efficace que pour les articles complets, mais c'est mieux que rien. Je ne me soucie plus non plus de ces scrapers, mais je n'approuve pas leurs trackbacks/pingbacks. :)
Au fait, faites-moi savoir quand vous allez sortir un nouveau thème WP afin que je puisse en faire une critique sur mon blog.
Mon prochain sera "Tasty Showcase" dont vous pouvez voir une démo ici. Je vous ferai savoir quand il sera publié.
Bonne astuce Leland ! J'utilise le plugin RSS footer sur mon blog mais je n'ai pas essayé de le combiner avec le plugin YARP. D'après les instructions et le concept, je pense que cela fonctionnerait si les scrapers récupèrent l'article complet. Cependant, j'ai vu beaucoup de scrapers qui n'utilisent que quelques lignes/phrases de la publication. Néanmoins, c'est toujours une bonne astuce que les blogueurs peuvent utiliser pour tirer parti des scrapers. Si vous ne pouvez pas les battre, utilisez-les. Hehe
Au fait, j'ai ajouté cet article à mon Résumé du week-end. 🙂
Salut Jaypee, merci d'avoir inclus l'article dans ton Résumé du week-end. 😀
Et oui, je ne pense pas que le pied de page RSS et les liens vers les articles similaires seraient affichés lorsque les scrapers ne prennent qu'un extrait (et pas l'article complet), donc tu as raison à ce sujet.
Personnellement, ces scrapers d'extraits ne me dérangent pas vraiment car non seulement ils ne prennent que quelques phrases, mais ils ont tendance à renvoyer également vers l'article original (sinon l'extrait sur leur site serait pratiquement inutile). Mon article parlait principalement des sites de scrapers d'articles complets.